How to Organize a Repository for an LLM Agent
More complex is better? I don’t think so. Five tiers of repository organization:
- Tier 0 — flat files. Everything in context. Prototypes, configs, small projects under 20 files.
- Tier 1 — text search + CLAUDE.md. How every AI coding agent works. Code projects up to 500 files.
- Tier 2 — docs-as-code. Structured documentation for teams. Stripe, Kubernetes, Django — no RAG needed.
- Tier 3 — LLM wiki, the Karpathy method. An LLM compiles a wiki from raw sources. Hundreds of documents.
- Tier 4 — wiki + RAG + knowledge graph. Semantic search and entity relationships. 500+ sources.
Don’t move to the next tier if the current one works.
LLM agents today solve radically different problems. One writes code in a ten-thousand-file repository. Another researches five hundred scientific papers. A third maintains documentation for two hundred people. Applying the same knowledge organization approach to all of these is overkill. I went through all five tiers on my own project — a university course on AI with hundreds of sources, dozens of artifacts, and a single author — and below I’ll explain what works at which scale.
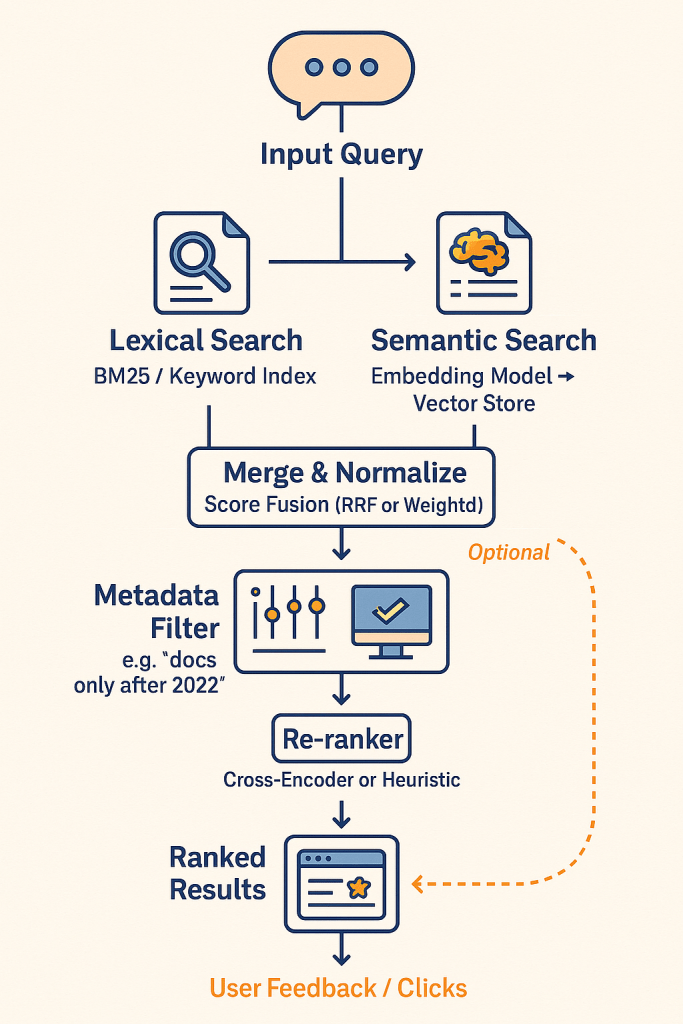
In 2024–2025, while the industry was building complex RAG pipelines and knowledge graphs, Cursor soared to $100M ARR with an approach built on an embedding index and text search over code. Not because text search is better than RAG — but because for code, it’s the right tool. Specifically for code.
In the world of knowledge organization for agents, people make two symmetrical mistakes. Some underinvest: 500 documents plus text search equals chaos — nothing gets found. Others overinvest: as Paul Hoke described, a developer deleted 2,000 lines of RAG code and accuracy jumped to 94%.
There is no “best” way to organize knowledge for an LLM agent. There are five tiers, each the best answer for its type of task and scale. Move to the next one only when the current tier breaks on a specific pain point. Context windows of all major models in 2026 have reached a million tokens and beyond — Gemini, Claude, Llama, GPT — and this shifts the threshold at which search infrastructure is even justified.
Tier 0: Everything Fits in Context — and That’s Great
Google NotebookLM lets you upload up to 50 sources and ask questions about them. Claude Projects from Anthropic is a feature where you add files to a “project” and the agent works with them in their entirety. Tens of millions of users. No RAG, no vector indexes. Just files in context. This isn’t an MVP — it’s a production architecture.
The Core Idea
All files are loaded entirely into the LLM’s context window. No search, no indexing. With 20 files of 200 lines each, that’s roughly 16,000 tokens — 1.6% of Claude’s window. As the Ahoi Kapptn team writes: “If your knowledge base is under 200K tokens (~500 pages), include it entirely in the prompt.”
Where this works perfectly: load 10 articles and ask questions — get synthesis with zero minutes of setup. A prototype with 5 files — the agent sees everything, accuracy is maximal. 15 infrastructure project configs — full context, zero latency. My AI course started exactly this way: two dozen files, everything fit in context, and the agent found what it needed instantly.
Example Structure
my-project/
notes.md # notes, ideas, drafts
data-analysis.py # all code — 3-5 files
config.yaml
research-paper-1.pdf # all sources right in the root
research-paper-2.pdf
When to Move On
One day you notice the agent starting to “forget” information. Research from Stanford and UC Berkeley (Liu et al., 2023) demonstrated the lost-in-the-middle effect: accuracy drops by 30% or more when relevant information lands in the middle of the context. Another study found that the effective context of all models on complex tasks turned out to be far smaller than advertised. The boundary: roughly 20 files or 50,000 tokens. If you feel this pain — time for the next tier. If not — stay put, you’re in the right place.
| Pattern | Anti-pattern |
|---|---|
| All files in one folder, no nesting | Setting up RAG for 5 documents |
| Maximally flat structure | Dumping 100 files into context “just in case” |
| Zero infrastructure, zero setup | Creating a folder hierarchy for 10 files |
Tier 1: Text Search + CLAUDE.md — How Every AI Coding Agent Works
Cursor. Claude Code. Windsurf. None of them require developers to spin up a vector database. All use text search as their core infrastructure. As BuildMVPFast writes: “Text search has quietly become the load-bearing infrastructure for how AI writes code.”
The Core Idea
At this tier, the project has a CLAUDE.md (or AGENTS.md, .cursorrules) that explains the codebase structure and conventions to the agent. The agent reads CLAUDE.md and understands the lay of the land — which directories are responsible for what, what naming conventions are in use. When a task arrives, the agent searches by keywords, finds the right files, then reads them in full for complete context. The directory structure itself becomes a navigation map.
At Tier 0, the agent sees everything but doesn’t know what matters. CLAUDE.md provides priorities. Search lets the agent read only the files it needs rather than loading all 500 into context. AGENTS.md is already standardized by the Linux Foundation, supported by OpenAI, Anthropic, Google, AWS, and Bloomberg. Over 60,000 repositories include it. As HumanLayer notes: “A CLAUDE.md written in 30 minutes gives the agent 80% of the context it needs.” To get started — create a CLAUDE.md and describe the architecture, key conventions, and how to run and test the project.
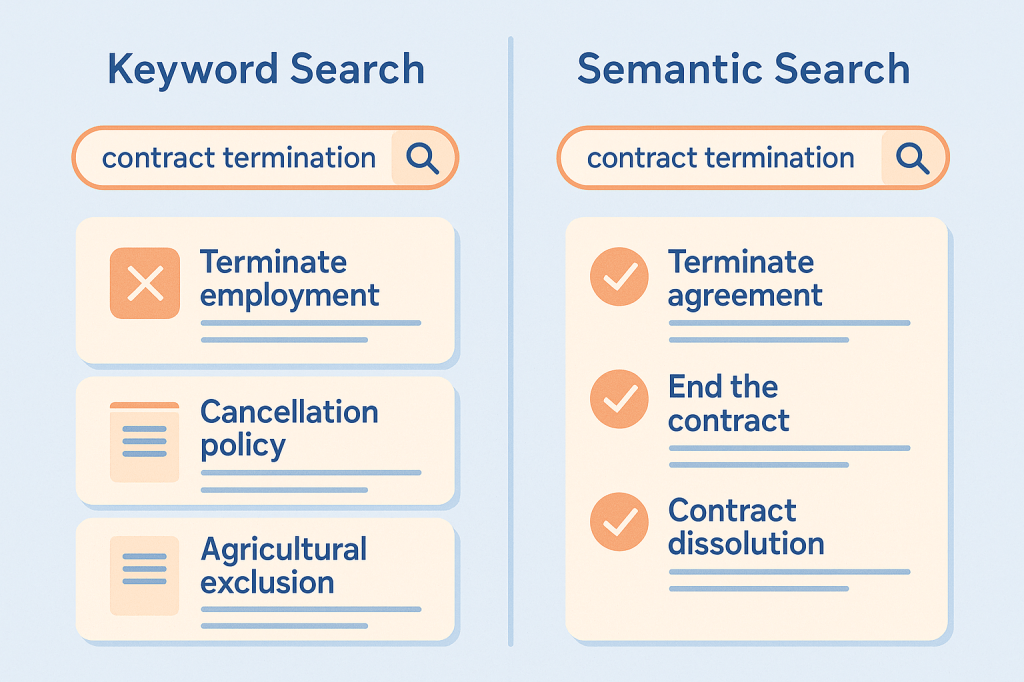
Text search objectively outperforms semantic search for exact matches. As ast-grep notes: ERROR_4532 in vector space is indistinguishable from ERROR_4533 — yet these are completely different errors. My AI course moved to this tier when sources exceeded twenty — search over exported documents was fast and accurate.
Example Structure
my-repo/
CLAUDE.md # ← instructions for the agent: architecture, conventions
AGENTS.md # standardized rules (can be used instead of CLAUDE.md)
src/ # project code
tests/ # tests alongside the code
docs/
architecture.md # keep documentation next to the code
adr/
001-use-postgres.md # architectural decisions in ADR format
When to Move On
You have 300 code files and search works great. Then a task comes in: find all GDPR requirements across research notes, legal documents, and meeting transcripts. Searching for the word “GDPR” finds 5 out of 20 relevant documents — the rest talk about “personal data”, “privacy regulation”, “data processing”. This is the polysemy problem: one concept, dozens of names. You don’t need a better search engine — you need structured navigation. The boundary: roughly 500 files, predominantly code. For non-code knowledge — PDFs, regulations, research — this model doesn’t work.
| Pattern | Anti-pattern |
|---|---|
| CLAUDE.md with architecture and conventions | Hoping the agent will “figure it out” |
| Consistent naming conventions | Different styles in different parts of the project |
| AGENTS.md + separate .md files per subdirectory | One giant 2,000-line CLAUDE.md |
| Text search for code and identifiers | Text search for concepts in prose |
Tier 2: Docs-as-Code — Structured Documentation for Teams
This tier is for projects where documentation is created by people for people, and the AI agent gets quality navigation for free. Stripe docs, Kubernetes (3,000+ pages), Django, Terraform — they serve millions of developers without RAG and have no plans to switch. As Mintlify notes: “At Stripe, a feature isn’t considered shipped until the documentation is written.”
The Core Idea
Documentation is organized by content type. The Diataxis framework divides it into 4 types — tutorials, how-to guides, reference, and explanation. When search finds the word “authentication” in 15 files, an agent without content typing has to read all 15. With Diataxis, it goes straight to how-to/configure-oauth.md. The framework is adopted by Cloudflare, Ubuntu, Django, and Gatsby.
The key advantage is a dual audience. A new team member reads the same documents as the AI agent. At Tier 3, the wiki is also human-readable but optimized for agent navigation. Here, there’s a single source of truth for both audiences. Plus, documentation gets indexed by search engines — a wiki behind an LLM or a RAG system is invisible to Google. To get started: sort your documents into the 4 Diataxis types and add a navigational index.md. One day for an average project.
Example Structure
docs/
index.md # ← navigation hub, start here
tutorials/
getting-started.md # learning material for newcomers
how-to/
configure-auth.md # instructions: "how to do X"
reference/
api/ # reference docs, often generated from code
explanation/
architecture.md # explanations: "why we chose X"
adr/
001-use-postgres.md # architectural decisions in ADR format
When to Move On
Maintenance cost — that’s what breaks this tier. At 200+ documents, classification becomes the bottleneck, and heterogeneous sources — scientific papers, transcripts, regulatory documents — don’t fit into neat templates.
| Pattern | Anti-pattern |
|---|---|
| Diataxis: 4 content types | A flat docs/ folder with no typing |
| Build-time link validation | Manually checking “did we break any links” |
| ADRs for architectural decisions | Decisions in chat, lost within a month |
Tier 3: The Karpathy Method — LLM as Librarian
According to ussumant/llm-wiki-compiler, 383 files became 13 articles — 81x compression. 130 meeting transcripts became a single 244-line digest — 503x compression. And this isn’t lossy summarization: the LLM finds connections between sources that a human would miss. As Karpathy wrote: “With ~100 articles and ~400K words, the LLM’s ability to navigate through summaries and index files is more than sufficient.”
The Core Idea
Three-layer architecture (Andrej Karpathy, April 2026): raw/ — immutable sources (PDFs, transcripts, notes), append-only, no editing; wiki/ — LLM-generated and LLM-maintained pages; index.md — a catalog of all wiki pages with one-line descriptions. The index is the search mechanism: the LLM scans it, finds the right page, reads it.
Three operations: Ingest — read a source, write a wiki page, update the index, update 10–15 related pages. Query — find an answer by scanning the index, save good answers as new pages. Lint — detect contradictions, orphaned pages, and outdated claims.
This is paradise for the solo researcher. One person plus one LLM replaces a documentation team. My AI course moved to this tier when sources reached the hundreds — a single maintainer manages the entire knowledge base through a wiki. Lint proactively detects outdated claims — unlike Tier 2 documentation, which goes stale silently. The entire “stack” is markdown in git. According to ussumant/llm-wiki-compiler, the agent starts a session with a compact index (~7.7K tokens) instead of hundreds of files (~47K) — an 84% reduction.
Karpathy’s gist garnered millions of views — it struck a nerve. Full implementations have already appeared: ussumant/llm-wiki-compiler (Claude Code plugin), atomicmemory/llm-wiki-compiler (TypeScript, concept extraction), xoai/sage-wiki (Go, hybrid text + vector search). As MindStudio notes: “If your knowledge base is under 50,000–100,000 tokens, there’s no technical reason to use RAG.”
If you need semantic search over heterogeneous sources but without wiki compilation, you can simply load documents into a local RAG system and get meaning-based search in a single evening. To start with a wiki: create raw/ and wiki/, add a CLAUDE.md with conventions from Karpathy’s gist. Ingest 10–20 documents per session — the wiki grows organically.
Example Structure
knowledge-base/
CLAUDE.md # ← schema and conventions from Karpathy's gist
index.md # catalog: one line per wiki page
log.md # operations log (append-only)
raw/ # immutable sources
paper-attention-2017.pdf
meeting-2026-03-15.txt
regulation-gdpr.md
wiki/ # LLM-generated pages (flat structure)
transformer-architectures.md
gdpr-compliance.md # ← the LLM found a connection to three sources
team-decisions-q1.md
# wiki is flat: LLM navigates via index.md, no subdirectories needed
When to Move On
You’re running a research project: 200 papers, 50 meeting transcripts, 30 regulatory documents. The wiki handles it beautifully. Then a request comes in: “find everything related to model fairness evaluation.” But in wiki pages, this topic is called “fairness metrics”; in source files, “bias evaluation”; in regulatory documents, “equity assessment.” The index is a precision tool: it finds what’s listed. Semantic discovery is not its job. At 500+ sources, the index itself exceeds 50,000 tokens and no longer fits in context.
| Pattern | Anti-pattern |
|---|---|
| raw/ append-only, wiki/ maintained by LLM | Editing the wiki by hand (breaks on recompilation) |
| One index.md with one-line descriptions | Nested indexes “for the future” with fewer than 100 pages |
| Incremental compilation | Full recompilation of 500 sources every time |
| Lint after every Ingest | Accumulating 100 sources and compiling them all at once |
Tier 4: When the Index Doesn’t Fit in Context — Add Semantics
In my AI course, the Karpathy-method wiki delivered a 7.6x reduction in tool calls and 9 out of 9 on completeness scores. But when I needed to find “everything about AI agents” across Russian-language documents, the wiki index didn’t help. The topic appeared under five different names in fifteen different places. Only semantic search found what text search and the index missed.
The Core Idea
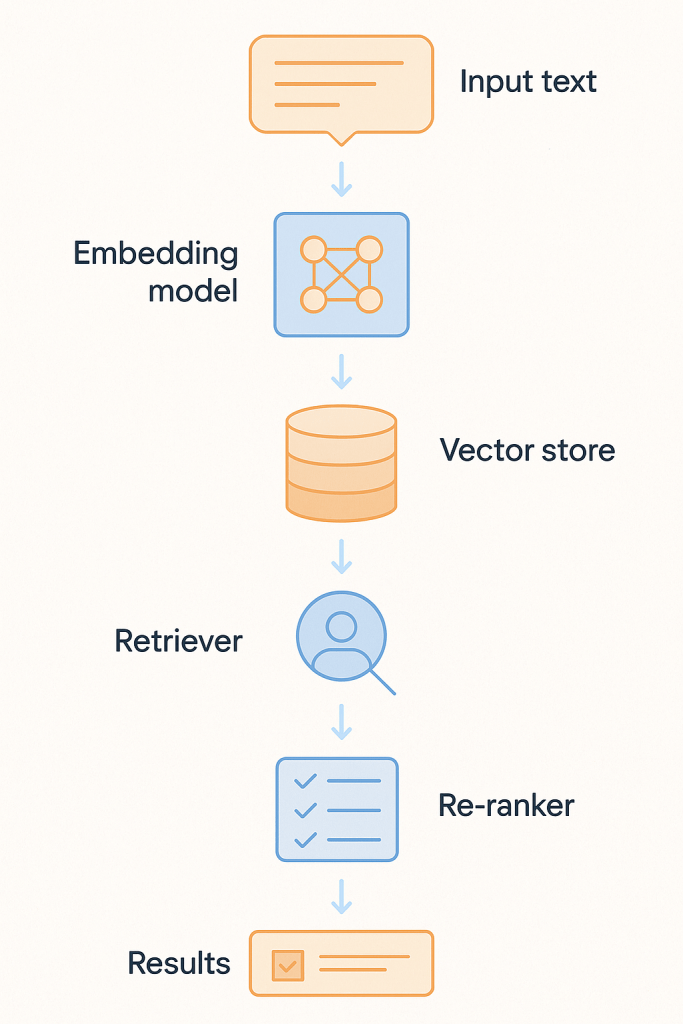
At this tier, the wiki (Tier 3) is supplemented with one or two layers. RAG (vector search) — semantic search via embeddings, finds “equity measures” when you search for “fairness metrics.” Knowledge graph (ontology) — structured relationships between entities: “paper X cites method Y, applied in domain Z.” The wiki remains the foundation — readable, navigable, in git. RAG and the graph are additional search layers on top, with results combined via Reciprocal Rank Fusion.
The cost isn’t necessarily high. In my course, I use local free tools: Oxigraph (an RDF store for the knowledge graph), mcp-local-rag (local semantic search with no external services) — everything lives in a single git repository, infrastructure cost is zero. For larger-scale tasks, LazyGraphRAG from Microsoft promises order-of-magnitude reductions in indexing costs. LightRAG delivers 70–90% of the quality at a hundredth of the cost.
Research library — the wiki compiles literature reviews, RAG finds papers by meaning, the graph tracks citation chains. Agent knowledge base — in my course: wiki for navigation, RAG for bilingual search (Russian and English), ontology on Oxigraph for traceability: “requirement -> lecture -> seminar -> assessment.” Team knowledge base — three years of accumulated experience: meeting transcripts, project documents, post-mortems; the wiki provides topic overviews, RAG finds “that time we already solved a similar problem.” Start with RAG on top of an existing wiki — one evening. Add the graph only when specific relational queries appear.
Example Structure
knowledge-base/
CLAUDE.md
index.md # wiki index (Tier 3)
raw/ # sources
papers/
by-topic/ # grouped by topic for convenience
meeting-notes/
regulations/
wiki/ # LLM-compiled pages
index/ # ← RAG index, add this first
ontology/ # knowledge graph, add when you need relationships
schema.ttl # classes and properties (I use Oxigraph)
store.ttl # data
queries/ # SPARQL queries for common questions
When You Need This
| You need RAG when | You need a knowledge graph when |
|---|---|
| Bilingual search (RU and EN) | Multi-hop queries (“papers by author X -> method Y -> domain Z”) |
| “Find something similar” (fuzzy discovery) | Traceability (requirement -> test -> coverage) |
| Wiki index exceeds 50,000 tokens | Aggregation (“all papers with no citations”) |
| Heterogeneous sources | Taxonomies and classifications |
| Pattern | Anti-pattern |
|---|---|
| Wiki as foundation + RAG/graph as layers | RAG instead of wiki (you lose navigation) |
| Local free tools (Oxigraph, local-rag) | Paying $200/mo for a vector DB to index 100 documents |
| Adding layers one at a time | Building the entire infrastructure upfront “for growth” |
| Graph for specific relational queries | Graph “because it looks cool” with no clear use cases |
How I Walked This Path
My AI course — hundreds of sources, dozens of artifacts, one maintainer.
I started at Tier 0: two dozen files, everything in context. Quickly outgrew it into Tier 1: search over exported documents. Tried RAG — got 10% precision on Russian-language queries. Tried an ontology — a beautiful schema, zero data.
I implemented Tier 3 — the Karpathy-method wiki: 7.6x reduction in tool calls, 9 out of 9 on completeness across test scenarios. Added RAG for semantic search on bilingual queries — but only after the wiki was working.
The key lesson: I tried to jump from Tier 1 to Tier 4 — and got beautifully empty infrastructure. Only when I went back to Tier 3 as the foundation and layered search on top did the system start working.
How to Determine the Right Structure
The entire selection framework boils down to two questions:
- How many sources do you have? (fewer than 20 / 20 to 500 / more than 500)
- What is it — code or documentation? (code / documentation for people / research, papers, heterogeneous sources)
| Scale \ Content | Code | Documentation for people | Research, heterogeneous |
|---|---|---|---|
| Fewer than 20 files | Tier 0 | Tier 0 | Tier 0 |
| 20–500 | Tier 1 (search + CLAUDE.md) | Tier 2 (docs-as-code) | Tier 3 (LLM wiki) |
| More than 500 | Tier 1 + indexed search | Tier 2 (scales to 3,000+) | Tier 3 + 4 (RAG/graph) |
Hybrid situations are the norm. “200 code files + 50 research papers” means code at Tier 1 (search + CLAUDE.md), papers at Tier 3 (wiki). Tiers aren’t mutually exclusive — they’re about content type.
Most of You Are at Tier 1. And That’s Fine
Entrepreneur Vamshi Reddy wrote to Karpathy: “Every business has a raw/ directory. Nobody has compiled it yet. There’s the product.”
I myself spent a sprint on a four-layer system with an ontology and SPARQL queries. Beautiful architecture. Graphs, relationships, validation. Then I opened the knowledge graph and discovered it was empty. Zero data. Right next to it sat a 40-line CLAUDE.md through which the agent had already been finding everything it needed for a week.
The right answer depends on the task. Tier 0 remains the best for small projects — NotebookLM serves millions of users without a single vector index. Tier 1 is for code. Stripe isn’t switching to RAG for their documentation, and they see no reason to. The Karpathy-method wiki is for researchers with hundreds of heterogeneous sources. And hybrid Tier 4 is justified where the cost of unfound information is measured in lost revenue or patients.
Each tier is not a step on a ladder but the right tool for its scale. A simple rule: if you’re not experiencing a specific pain point at your current tier — you’re in the right place.
Как организовать репозиторий для LLM-агента
Чем сложнее, тем лучше? Не думаю. Пять уровней организации репозитория:
- Уровень 0 — плоские файлы. Всё в контексте. Прототипы, конфиги, малые проекты до 20 файлов.
- Уровень 1 — текстовый поиск + CLAUDE.md. Так работают все AI-кодинг-агенты. Кодовые проекты до 500 файлов.
- Уровень 2 — docs-as-code. Структурированная документация для команд. Stripe, Kubernetes, Django — без RAG.
- Уровень 3 — LLM-вики по методу Карпати. LLM компилирует вики из сырых источников. Сотни документов.
- Уровень 4 — вики + RAG + граф знаний. Семантический поиск и связи. 500+ источников.
Не переходите на следующий, если хватает текущего.
LLM-агенты сегодня решают радикально разные задачи. Один агент пишет код в репозитории на десять тысяч файлов. Другой исследует пятьсот научных публикаций. Третий поддерживает документацию для двухсот человек. Применять один и тот же подход к организации знаний для всех этих задач — это слишком. Я прошёл все пять уровней на собственном проекте — учебном курсе по AI с сотнями источников, десятками артефактов и одним автором — и дальше расскажу, что работает на каком масштабе.
В 2024–2025 годах, пока индустрия строила сложные RAG-пайплайны и графы знаний, Cursor взлетел до $100M ARR с подходом, в основе которого — индекс эмбеддингов и текстовый поиск по коду. Не потому что текстовый поиск лучше RAG. А потому что для кода это правильный инструмент. Именно для кода.
В мире организации знаний для агентов люди совершают две симметричные ошибки. Одни недоинвестируют: 500 документов и текстовый поиск — хаос, ничего не находится. Другие переинвестируют: как описал Пол Хоук, разработчик удалил 2000 строк RAG-кода, и точность подскочила до 94%.
Нет «лучшего» способа организовать знания для LLM-агента. Есть пять уровней, каждый из которых — лучший ответ для своего типа задачи и масштаба. Переходить на следующий стоит только когда текущий ломается на конкретной болевой точке. Контекстные окна всех основных моделей в 2026 году достигли миллиона токенов и больше — Gemini, Claude, Llama, GPT — и это сдвигает порог, на котором инфраструктура поиска вообще оправдана.
Уровень 0: Всё помещается в контекст — и это прекрасно
Google NotebookLM позволяет загрузить до 50 источников и задавать вопросы по ним. Claude Projects от Anthropic — функция, где вы добавляете файлы в «проект» и агент работает с ними целиком. Десятки миллионов пользователей. Никакого RAG, никаких векторных индексов. Просто файлы в контексте. Это не MVP — это рабочая архитектура.
Суть подхода
Все файлы целиком загружаются в контекстное окно LLM. Никакого поиска, никакой индексации. При 20 файлах по 200 строк это около 16 тысяч токенов — 1.6% окна Claude. Как пишет команда Ahoi Kapptn: «Если ваша база знаний меньше 200 тысяч токенов (около 500 страниц), включите её целиком в промпт».
Где это работает идеально: загрузили 10 статей — задавайте вопросы, получайте синтез за ноль минут настройки. Прототип на 5 файлов — агент видит всё, точность максимальна. 15 конфигов инфраструктурного проекта — полный контекст, нулевая задержка. Мой курс по AI начинался именно так: два десятка файлов, всё помещалось в контекст, и агент находил нужное мгновенно.
Пример структуры
my-project/
notes.md # заметки, идеи, черновики
data-analysis.py # весь код — 3-5 файлов
config.yaml
research-paper-1.pdf # все источники прямо в корне
research-paper-2.pdf
Когда переезжать
Однажды вы замечаете, что агент начинает «забывать» информацию. Исследование Stanford и UC Berkeley (Liu et al., 2023) показало эффект «потери в середине»: точность падает на 30% и больше, когда нужная информация оказывается в середине контекста. Другая работа зафиксировала, что эффективный контекст всех моделей на сложных задачах оказался гораздо меньше рекламируемого. Граница: примерно 20 файлов или 50 тысяч токенов. Если чувствуете эту боль — пора на следующий уровень. Если нет — оставайтесь, вы на правильном месте.
| Паттерн | Антипаттерн |
|---|---|
| Все файлы в одной папке, без вложенности | Настраивать RAG для 5 документов |
| Максимально плоская структура | Складывать 100 файлов в контекст «про запас» |
| Ноль инфраструктуры, ноль настройки | Создавать иерархию папок для 10 файлов |
Уровень 1: Текстовый поиск + CLAUDE.md — так работают все AI-кодинг-агенты
Cursor. Claude Code. Windsurf. Ни один из них не требует от разработчика поднимать векторную базу данных. Все используют текстовый поиск как основную инфраструктуру. Как пишет BuildMVPFast: «Текстовый поиск тихо стал несущей инфраструктурой для того, как AI пишет код».
Суть подхода
На этом уровне проект имеет CLAUDE.md (или AGENTS.md, .cursorrules), который объясняет агенту структуру и конвенции кодовой базы. Агент читает CLAUDE.md и понимает, где что лежит — какие директории за что отвечают, какие конвенции именования используются. Когда приходит задача, агент ищет по ключевым словам, находит подходящие файлы, а затем зачитывает их целиком, чтобы получить полный контекст. Структура директорий сама по себе становится навигационной картой.
На уровне 0 агент видит всё — но не знает, что важно. CLAUDE.md даёт приоритеты. Поиск позволяет агенту читать только нужные файлы, а не загружать все 500 в контекст. AGENTS.md уже стандартизирован Linux Foundation, поддерживается OpenAI, Anthropic, Google, AWS, Bloomberg. Более 60 тысяч репозиториев включают его. Как отмечает HumanLayer: «CLAUDE.md за 30 минут даёт агенту 80% нужного контекста». Чтобы начать — создайте CLAUDE.md и опишите архитектуру, ключевые конвенции, как запустить и протестировать проект.
Текстовый поиск объективно превосходит семантический для точных совпадений. Как отмечает ast-grep: ERROR_4532 в векторном пространстве неотличим от ERROR_4533 — а это совершенно разные ошибки. Мой курс по AI перешёл на этот уровень, когда источников стало больше двадцати — поиск по экспортированным документам работал быстро и точно.
Пример структуры
my-repo/
CLAUDE.md # ← инструкции агенту: архитектура, конвенции
AGENTS.md # стандартизованные правила (можно вместо CLAUDE.md)
src/ # код проекта
tests/ # тесты рядом с кодом
docs/
architecture.md # держите документацию рядом с кодом
adr/
001-use-postgres.md # архитектурные решения в формате ADR
Когда переезжать
У вас 300 файлов кода и поиск работает отлично. Потом приходит задача: найти все требования GDPR в исследовательских заметках, юридических документах и протоколах встреч. Поиск по слову «GDPR» находит 5 из 20 релевантных документов — остальные говорят о «персональных данных», «privacy regulation», «обработке ПДн». Это проблема полисемии: одно понятие, десятки названий. Вам нужна не лучшая поисковая система, а структурированная навигация. Граница: примерно 500 файлов, преимущественно код. Для не-кодовых знаний — PDF, нормативные документы, исследования — эта модель не работает.
| Паттерн | Антипаттерн |
|---|---|
| CLAUDE.md с архитектурой и конвенциями | Надеяться, что агент «сам разберётся» |
| Единообразные правила именования | Разные стили в разных частях проекта |
| AGENTS.md + отдельные .md по поддиректориям | Один гигантский CLAUDE.md на 2000 строк |
| Текстовый поиск для кода и идентификаторов | Текстовый поиск для концепций в прозе |
Уровень 2: Docs-as-code — структурированная документация для команд
Этот уровень — для проектов, где документация создаётся людьми для людей, а AI-агент получает качественную навигацию бесплатно. Stripe docs, Kubernetes (3000+ страниц), Django, Terraform — обслуживают миллионы разработчиков без RAG и не собираются переходить. Как отмечает Mintlify: «В Stripe фича не считается выпущенной, пока не написана документация».
Суть подхода
Документация организована по типу контента. Фреймворк Diátaxis делит её на 4 типа — обучение, инструкции, справочник, объяснение. Когда поиск находит слово «authentication» в 15 файлах, агент без типизации вынужден читать все 15. С Diátaxis — сразу идёт в how-to/configure-oauth.md. Фреймворк принят Cloudflare, Ubuntu, Django, Gatsby.
Главное преимущество — двойная аудитория. Новый член команды читает те же документы, что и AI-агент. На уровне 3 вики тоже читаема, но оптимизирована под навигацию агента. Здесь — один источник правды для обеих аудиторий. Плюс документация индексируется поисковиками — вики за LLM или RAG-система для Google невидимы. Чтобы начать: рассортируйте документы по 4 типам Diátaxis, добавьте навигационный index.md. Один день для среднего проекта.
Пример структуры
docs/
index.md # ← навигационный хаб, начните здесь
tutorials/
getting-started.md # обучение для новичков
how-to/
configure-auth.md # инструкции: «как сделать X»
reference/
api/ # справочник, часто генерируется из кода
explanation/
architecture.md # объяснения: «почему мы выбрали X»
adr/
001-use-postgres.md # архитектурные решения в формате ADR
Когда переезжать
Стоимость поддержания — вот что ломает этот уровень. При 200+ документах классификация становится узким местом, а разнородные источники — научные публикации, транскрипты, нормативные документы — не укладываются в аккуратные шаблоны.
| Паттерн | Антипаттерн |
|---|---|
| Diátaxis: 4 типа контента | Плоская папка docs/ без типизации |
| Валидация ссылок при сборке | Ручная проверка «не сломали ли ссылки» |
| ADR для архитектурных решений | Решения в чатах, потерянные через месяц |
Уровень 3: Метод Карпати — LLM как библиотекарь
По данным ussumant/llm-wiki-compiler, 383 файла превратились в 13 статей — 81-кратная компрессия. 130 транскриптов совещаний стали одним дайджестом на 244 строки — 503-кратное сжатие. И это не выжимка с потерями: LLM находит связи между источниками, которые человек бы пропустил. Как написал Карпати: «При ~100 статьях и ~400K слов способности LLM навигировать через саммари и индексные файлы более чем достаточно».
Суть подхода
Трёхслойная архитектура (Andrej Karpathy, апрель 2026): raw/ — неизменяемые источники (PDF, транскрипты, заметки), только добавление, без редактирования; wiki/ — LLM-сгенерированные и LLM-поддерживаемые страницы; index.md — каталог всех вики-страниц с однострочными описаниями. Индекс — это и есть механизм поиска: LLM сканирует его, находит нужную страницу, читает.
Три операции: Ingest — прочитать источник, написать вики-страницу, обновить индекс, обновить 10–15 связанных страниц. Query — найти ответ через сканирование индекса, сохранить хорошие ответы как новые страницы. Lint — обнаружить противоречия, осиротевшие страницы, устаревшие утверждения.
Это рай для соло-исследователя. Один человек плюс один LLM заменяют документационную команду. Мой курс по AI перешёл на этот уровень, когда источников стало сотни — один мейнтейнер управляет всей базой знаний через вики. Lint обнаруживает устаревшие утверждения проактивно — в отличие от документации уровня 2, которая устаревает молча. Весь «стек» — markdown в git. По данным ussumant/llm-wiki-compiler, агент начинает сессию с компактного индекса (~7.7K токенов) вместо сотен файлов (~47K) — сокращение на 84%.
Гист Карпати набрал миллионы просмотров — он попал в нерв. Уже появились полноценные реализации: ussumant/llm-wiki-compiler (плагин для Claude Code), atomicmemory/llm-wiki-compiler (TypeScript, извлечение концепций), xoai/sage-wiki (Go, гибридный текстовый + векторный поиск). Как отмечает MindStudio: «Если ваша база знаний меньше 50–100 тысяч токенов, нет технической причины использовать RAG».
Если вам нужен семантический поиск по разнородным источникам, но без вики-компиляции — можно просто загрузить документы в локальный RAG и получить поиск по смыслу за один вечер. Чтобы начать с вики: создайте raw/ и wiki/, добавьте CLAUDE.md с конвенциями из гиста Карпати. Загружайте по 10–20 документов за сессию — вики растёт органически.
Пример структуры
knowledge-base/
CLAUDE.md # ← схема и конвенции из гиста Карпати
index.md # каталог: одна строка — одна вики-страница
log.md # журнал операций (только дополнение)
raw/ # неизменяемые источники
paper-attention-2017.pdf
meeting-2026-03-15.txt
regulation-gdpr.md
wiki/ # LLM-сгенерированные страницы (плоская структура)
transformer-architectures.md
gdpr-compliance.md # ← LLM нашёл связь с тремя источниками
team-decisions-q1.md
# вики плоская: LLM навигирует через index.md, подпапки не нужны
Когда переезжать
Вы ведёте исследовательский проект: 200 публикаций, 50 протоколов встреч, 30 нормативных документов. Вики отлично справляется. Потом приходит запрос: «найди всё связанное с оценкой справедливости моделей». Но в вики-страницах эта тема называется «метрики справедливости», в исходниках — «bias evaluation», в нормативных документах — «оценка корректности». Индекс — точный инструмент: он находит то, что перечислено. Семантическое обнаружение — не его задача. При 500+ источниках сам индекс превышает 50 тысяч токенов и перестаёт помещаться в контекст.
| Паттерн | Антипаттерн |
|---|---|
| raw/ только дополнение, wiki/ поддерживается LLM | Редактировать вики руками (сломается при перекомпиляции) |
| Один index.md с однострочными описаниями | Вложенные индексы «на будущее» при менее 100 страниц |
| Инкрементальная компиляция | Полная перекомпиляция 500 источников каждый раз |
| Lint после каждого Ingest | Копить 100 источников и потом компилировать разом |
Уровень 4: Когда индекс не помещается в контекст — добавляем семантику
В моём курсе по AI вики по методу Карпати дала 7.6-кратное сокращение обращений к инструментам и 9 из 9 по полноте ответов. Но когда понадобилось найти «всё про AI-агентов» по русскоязычным документам — вики-индекс не помог. Тема упоминалась под пятью разными названиями в пятнадцати разных местах. Только семантический поиск нашёл то, что текстовый поиск и индекс пропустили.
Суть подхода
На этом уровне вики (уровень 3) дополняется одним или двумя слоями. RAG (векторный поиск) — семантический поиск по векторным представлениям, находит «equity measures» когда ищешь «метрики справедливости». Граф знаний (онтология) — структурированные связи между сущностями: «статья X цитирует метод Y, применённый в домене Z». Вики остаётся основой — читаемой, навигируемой, в git. RAG и граф — дополнительные слои поиска поверх неё, результаты объединяются через Reciprocal Rank Fusion.
Стоимость не обязательно высокая. В моём курсе я использую локальные бесплатные инструменты: Oxigraph (RDF-хранилище для графа знаний), mcp-local-rag (локальный семантический поиск без внешних сервисов) — всё живёт в одном git-репозитории, стоимость инфраструктуры равна нулю. Для более масштабных задач LazyGraphRAG от Microsoft обещает снижение стоимости индексации на порядки. LightRAG даёт 70–90% качества за сотую долю цены.
Научная библиотека — вики компилирует литературные обзоры, RAG находит публикации по смыслу, граф отслеживает цепочки цитирования. Агентская база знаний — в моём курсе: вики для навигации, RAG для двуязычного поиска (русский и английский), онтология на Oxigraph для трассировки «требование → лекция → семинар → оценка». Командная база знаний — три года накопленного опыта: протоколы встреч, проектные документы, пост-мортемы; вики даёт обзоры по темам, RAG находит «тот случай, когда мы уже решали похожую проблему». Начните с RAG поверх существующей вики — один вечер. Граф добавляйте только когда появятся конкретные запросы на связи.
Пример структуры
knowledge-base/
CLAUDE.md
index.md # вики-индекс (уровень 3)
raw/ # источники
papers/
by-topic/ # группировка по темам для удобства
meeting-notes/
regulations/
wiki/ # LLM-компилированные страницы
index/ # ← RAG-индекс, добавьте первым
ontology/ # граф знаний, добавьте когда нужны связи
schema.ttl # классы и свойства (я использую Oxigraph)
store.ttl # данные
queries/ # SPARQL-запросы для типовых вопросов
Когда это нужно
| Нужен RAG когда | Нужен граф знаний когда |
|---|---|
| Двуязычный поиск (RU и EN) | Многошаговые запросы («публикации автора X → метод Y → домен Z») |
| «Найди похожее» (нечёткое обнаружение) | Трассировка (требование → тест → покрытие) |
| Индекс вики больше 50 тысяч токенов | Агрегация («все публикации без цитирований») |
| Разнородные источники | Таксономии и классификации |
| Паттерн | Антипаттерн |
|---|---|
| Вики как основа + RAG/граф как слои | RAG вместо вики (теряете навигацию) |
| Локальные бесплатные инструменты (Oxigraph, local-rag) | Платная векторная БД за $200/мес для 100 документов |
| Добавлять слои по одному | Строить всю инфраструктуру сразу «на вырост» |
| Граф для конкретных запросов на связи | Граф «потому что красиво» без чётких задач |
Как я прошёл этот путь
Мой курс по AI — сотни источников, десятки артефактов, один мейнтейнер.
Начинал с уровня 0: два десятка файлов, всё в контексте. Быстро перерос в уровень 1: поиск по экспортированным документам. Попробовал RAG — получил 10% точности на русскоязычных запросах. Попробовал онтологию — красивая схема, ноль данных.
Реализовал уровень 3 — вики по методу Карпати: 7.6-кратное сокращение обращений к инструментам, 9 из 9 по полноте на тестовых сценариях. Добавил RAG для семантического поиска по двуязычным запросам — но только после того, как вики заработала.
Ключевой урок: я попробовал перепрыгнуть с уровня 1 на уровень 4 — и получил красивую пустую инфраструктуру. Только когда вернулся к уровню 3 как базе и добавил слои поиска сверху — система заработала.
Как определить нужную структуру
Весь фреймворк выбора сводится к двум вопросам:
- Сколько у вас источников? (менее 20 / от 20 до 500 / более 500)
- Что это — код или документация? (код / документация для людей / исследования, публикации, разнородные источники)
| Масштаб \ Контент | Код | Документация для людей | Исследования, разнородные |
|---|---|---|---|
| Менее 20 файлов | Уровень 0 | Уровень 0 | Уровень 0 |
| 20–500 | Уровень 1 (поиск + CLAUDE.md) | Уровень 2 (docs-as-code) | Уровень 3 (LLM-вики) |
| Более 500 | Уровень 1 + индексированный поиск | Уровень 2 (до 3000+) | Уровень 3 + 4 (RAG/граф) |
Гибридные ситуации — норма. «200 файлов кода + 50 научных публикаций» — код на уровне 1 (поиск + CLAUDE.md), публикации на уровне 3 (вики). Уровни не монопольны, они про тип контента.
Большинство из вас на уровне 1. И это нормально
Предприниматель Вамши Редди написал Карпати: «У каждого бизнеса есть директория raw/. Никто её ещё не скомпилировал. Вот и продукт».
Я сам потратил спринт на четырёхслойную систему с онтологией и SPARQL-запросами. Красивая архитектура. Графы, связи, валидация. А потом открыл граф знаний и обнаружил, что он пуст. Ноль данных. Рядом лежал CLAUDE.md на 40 строк, через который агент уже неделю находил всё нужное.
Правильный ответ зависит от задачи. Уровень 0 пока остаётся лучшим для малых проектов — NotebookLM обслуживает миллионы пользователей без единого векторного индекса. Уровень 1 — для кода. Stripe пока не переходит на RAG для своей документации, и пока не видит причин. Вики по методу Карпати — для исследователей с сотнями разнородных источников. А гибридный уровень 4 оправдан там, где стоимость ненайденной информации измеряется в потерянных деньгах или пациентах.
Каждый уровень — не ступенька лестницы, а правильный инструмент для своего масштаба. Простое правило: если не испытываете конкретную боль текущего уровня — вы на правильном месте.