Latest practices, real architectures, and when NOT to use RAG
🎯The Paradigm Shift
💰 The $50 Million Question
Picture this: A mahogany-paneled boardroom on the 47th floor of a Manhattan skyscraper. The CTO stands before the executive team, laser pointer dancing across slides filled with AI acronyms.
“We need RAG everywhere!” she declares, her voice cutting through the morning air. “Our competitors are using it. McKinsey says it’s transformative. We’re allocating $50 million for company-wide RAG implementation.”
The board members nod sagely. The CFO scribbles numbers. The CEO leans forward, ready to approve.
But here’s what nobody in that room wants to admit: They might be about to waste $50 million solving the wrong problem.
🎬 The Netflix Counter-Example
Consider Netflix. The streaming giant:
- 📊 Processes 100 billion events daily
- 👥 Serves 260 million subscribers
- 💵 Generates $33.7 billion in annual revenue
- 🎯 Drives 80% of viewing time through recommendations
And guess what? They don’t use RAG for recommendations.
Not because they can’t afford it or lack the technical expertise—but because collaborative filtering, matrix factorization, and deep learning models simply work better for their specific problem.
🤔 The Real Question
This uncomfortable truth reveals what companies should actually be asking:
❌ “How do we implement RAG?“
❌ “Which vector database should we choose?“
❌ “Should we use GPT-4 or Claude?“
✅ “What problem are we actually trying to solve?”
📈 Success Stories That Matter
The most successful RAG implementations demonstrate clear problem-solution fit:
🏦 Morgan Stanley
- Problem: 70,000+ research reports, impossible to search effectively
- Solution: RAG-powered AI assistant
- Result: 40,000 employees served, 15 hours saved weekly per person
🏥 Apollo 24|7
- Problem: 40 years of medical records, complex patient histories
- Solution: Clinical intelligence engine with context-aware RAG
- Result: 4,000 doctor queries daily, 99% accuracy, ₹21:₹1 ROI
💳 JPMorgan Chase
- Problem: Real-time fraud detection across millions of transactions
- Solution: GraphRAG with behavioral analysis
- Result: 95% reduction in false positives, protecting 50% of US households
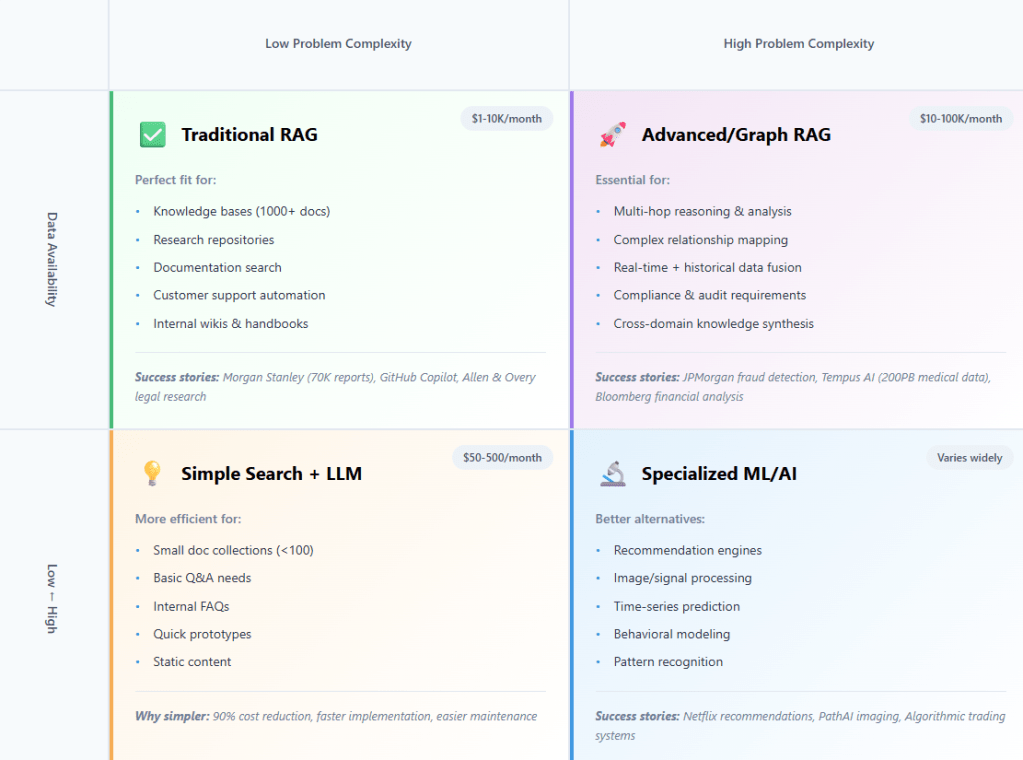
🎯 The AI Decision Matrix
🔑 The Key Insight
“RAG isn’t magic. It’s engineering.”
And like all engineering decisions, success depends on matching the solution to the problem, not the other way around. The companies generating billions from AI didn’t start with perfect RAG. They started with clear problems and built solutions that fit.
📊 When RAG Makes Sense: The Success Patterns
✅ Perfect RAG Use Cases:
- Large knowledge repositories (1,000+ documents) requiring semantic search
- Expert knowledge systems where context and nuance matter
- Compliance-heavy domains needing traceable answers with citations
- Dynamic information that updates frequently but needs historical context
- Multi-source synthesis combining internal and external data
❌ When to Look Elsewhere:
- Structured data problems (use SQL/traditional databases)
- Pure pattern matching (use specialized ML models)
- Real-time sensor data (use streaming analytics)
- Small, static datasets (use simple search)
- Recommendation systems (use collaborative filtering)
The revolution isn’t about RAG everywhere—it’s about RAG where it matters.
📝 THE REALITY CHECK – “When RAG Wins (And When It Doesn’t)”
The Three Scenarios
💸 Scenario A: RAG Was Overkill
“The $15,000 Monthly Mistake”
The Case: Startup Burning Cash on Vector Databases
Meet TechFlow, a 25-person SaaS startup that convinced themselves they needed enterprise-grade RAG. Their use case? A company knowledge base with exactly 97 documents—employee handbook, product specs, and some technical documentation.
Their “AI-first” CTO installed the full stack:
- 🗄️ Pinecone Pro: $8,000/month
- 🤖 OpenAI API costs: $4,000/month
- ☁️ AWS infrastructure: $2,500/month
- 👨💻 Two full-time ML engineers: $30,000/month combined
Total monthly burn: $44,500 for what should have been a $200 problem.
The Better Solution: Simple Search + GPT-3.5
What they actually needed:
- Elasticsearch (free tier): $0
- GPT-3.5-turbo API: $50/month
- Simple web interface: 2 days of dev work
- Total cost: $50/month (99.8% cost reduction)
The tragic irony? Their $50 solution delivered faster responses and better user experience than their over-engineered RAG stack.
The Lesson: “Don’t Use a Ferrari for Grocery Shopping”
Warning Sign: If your document count has fewer digits than your monthly AI bill, you’re probably over-engineering.
🏆 Scenario B: RAG Was Perfect
“The Morgan Stanley Success Story”
The Case: 70,000 Research Reports, 40,000 Employees
Morgan Stanley faced a genuine needle-in-haystack problem:
- 📚 70,000+ proprietary research reports spanning decades
- 👥 40,000 employees (50% of workforce) needing instant access
- ⏱️ Complex financial queries requiring expert-level synthesis
- 🔄 Real-time market data integration essential
Traditional search was failing catastrophically. Investment advisors spent hours hunting for the right analysis while clients waited.
Why RAG Won: The Perfect Storm of Requirements
✅ Large Corpus: 70K documents = semantic search essential
✅ Expert Knowledge: Financial analysis requires nuanced understanding
✅ Real-time Updates: Market conditions change by the minute
✅ User Scale: 40K employees = infrastructure investment justified
✅ High-Value Use Case: Faster client responses = millions in revenue
The Architecture: Hybrid Search + Re-ranking + Custom Training
Financial Reports
→ Domain-specific embedding model
→ Vector database (semantic search) + Traditional search (exact terms)
→ Cross-encoder re-ranking
→ GPT-4 with financial training
→ Contextual response with citations
The Results: Transformational Impact
- ⚡ Response time: Hours → Seconds
- 📈 User adoption: 50% of entire workforce
- ⏰ Time savings: 15 hours per week per employee
- 💰 ROI: Multimillion-dollar productivity gains
🩺 Scenario C: RAG Wasn’t Enough
“The Medical Diagnosis Reality Check”
The Case: Real-time Patient Monitoring
MedTech Innovation wanted to build an AI diagnostic assistant for ICU patients. Their initial plan? Pure RAG querying medical literature based on patient symptoms.
The reality check came fast:
- 📊 Real-time vitals: Heart rate, blood pressure, oxygen levels
- 🩸 Lab results: Constantly updating biochemical markers
- 💊 Drug interactions: Dynamic medication effects
- ⏰ Temporal patterns: Symptom progression over time
- 🧬 Genetic factors: Patient-specific risk profiles
RAG could handle the medical literature lookup, but 90% of the diagnostic value came from real-time data analysis that required specialized ML pipelines.
The Better Solution: Specialized ML Pipeline with RAG as Component
Real-time sensors → Time-series ML models → Risk scoring
↓
Historical EHR → Pattern recognition → Trend analysis
↓
Symptoms + vitals → RAG medical literature → Evidence synthesis
↓
Combined AI reasoning → Diagnostic suggestions + Literature support
The Lesson: “RAG is a Tool, Not a Complete Solution”
RAG became one valuable component in a larger AI ecosystem, not the centerpiece. The startup’s pivot to this architecture secured $12M Series A funding and FDA breakthrough device designation.
📊 Business Impact Spectrum
| Solution Type | Implementation Cost | Monthly Operating | Typical ROI Timeline | Sweet Spot Use Cases |
|---|---|---|---|---|
| Simple Search + LLM | $5K-15K | $50-500 | 1-2 months | <100 docs, internal FAQs |
| Traditional RAG | $15K-50K | $1K-10K | 3-6 months | 1K+ docs, expert knowledge |
| Advanced RAG | $50K-200K | $10K-100K | 6-12 months | Complex reasoning, compliance |
| Custom ML + RAG | $200K+ | $100K+ | 12+ months | Mission-critical, specialized domains |
“60% of ‘RAG projects’ don’t need RAG—they need better search.”
The uncomfortable truth from three years of production deployments: Most organizations rush to RAG because it sounds sophisticated, when their real problem is that their existing search is terrible.
The $50M boardroom lesson? Before building RAG, audit what you already have. That “innovative AI transformation” might just be a well-configured Elasticsearch instance away.
Next up: For the 40% of cases where RAG is the right answer, let’s examine how industry leaders actually architect these systems—and the patterns that separate billion-dollar successes from expensive failures.
🏗️ THE NEW ARCHITECTURES – “How Industry Leaders Actually Build RAG”
🏗️ The Evolution in Practice
The boardroom fantasy of “plug-and-play RAG” died quickly in 2024. What emerged instead were three distinct architectural patterns that separate billion-dollar successes from expensive failures. These aren’t theoretical frameworks—they’re battle-tested systems processing petabytes of data and serving millions of users daily.
The evolution follows a clear trajectory: from generic chatbots to domain-specific intelligence engines that understand context, relationships, and real-time requirements. The winners didn’t just implement RAG—they architected RAG ecosystems tailored to their specific business challenges.
🧬 Pattern 1: The Hybrid Intelligence Model
“When RAG Meets Specialized ML”
Tempus AI – Precision Medicine at Scale
Tempus AI didn’t just build a medical RAG system—they created a hybrid intelligence platform that processes 200+ petabytes of multimodal clinical data while serving 65% of US academic medical centers.
The challenge was existential: cancer research requires understanding temporal relationships (how treatments evolve), spatial patterns (tumor progression), and literature synthesis (latest research findings). Pure RAG couldn’t handle the temporal aspects. Pure ML couldn’t synthesize research literature. The solution? Architectural fusion.

Architecture Innovation: Multi-Modal Intelligence Stack
🗄️ Graph Databases for patient relationship mapping:
Patient A → Similar genetic profile → Patient B
→ Successful treatment path → Protocol C
→ Literature support → Study XYZ
🔍 Vector Search for literature matching:
- Custom biomedical embeddings trained on 15+ million pathologist annotations
- Cross-modal retrieval linking pathology images to clinical outcomes
- Real-time integration with PubMed and clinical trial databases
📊 Time-Series Databases for temporal pattern recognition:
- Treatment response tracking over months/years
- Biomarker progression analysis
- Survival outcome prediction models
The Business Breakthrough
📈 Revenue Results:
- $693.4M revenue in 2024 (79% growth projected for 2025)
- $8.5B market valuation driven by AI capabilities
- 5 percentage point increase in clinical trial success probability for pharma partners
The hybrid approach solved what pure RAG couldn’t: context-aware medical intelligence that understands both current patient state and historical patterns.
💰 Pattern 2: The Domain-Specific Specialist
“When Generic Models Hit Their Limits”
Bloomberg’s Financial Intelligence Engine
Bloomberg faced a problem that perfectly illustrates why generic RAG fails at enterprise scale. Financial markets generate 50,000+ news items daily, while their 50-billion parameter BloombergGPT needed to process 700+ billion financial tokens with millisecond-accurate timing.
The insight: financial language isn’t English. Terms like “tight spreads,” “flight to quality,” and “basis points” have precise meanings that generic models miss. Bloomberg’s solution? Complete domain specialization.
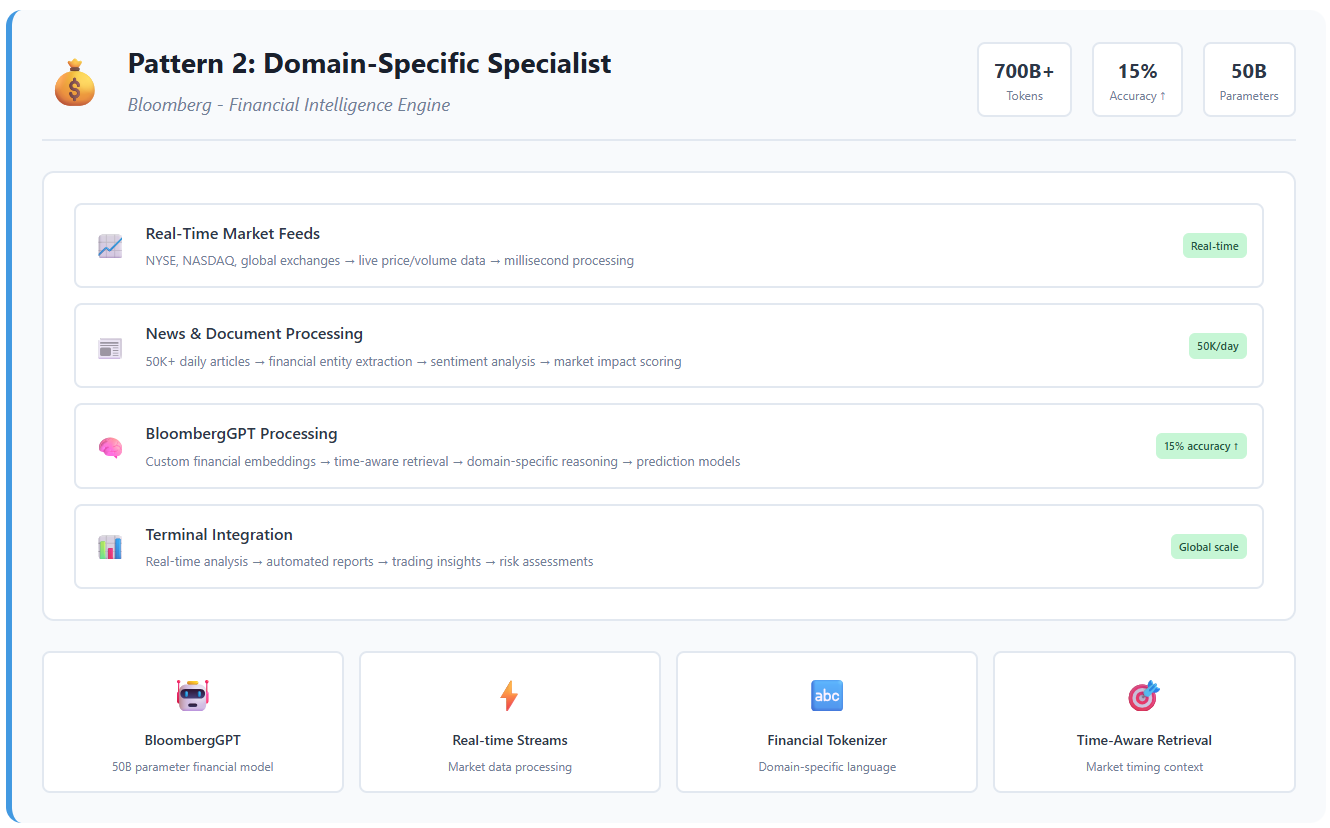
Architecture Innovation: Financial-Native Intelligence
🧠 Custom Financial Embedding Models:
- Trained exclusively on financial texts and market data
- Understanding of temporal context (Q1 vs Q4 reporting cycles)
- Entity resolution for companies, currencies, and financial instruments
⏰ Time-Aware Retrieval for market timing:
Query: “Apple earnings impact”
Context: Market hours, earnings season, recent volatility
Retrieval: Weight recent analysis higher, flag market-moving events
Response: Time-contextualized with market timing considerations
🔤 Specialized Tokenization for financial terms:
- Numeric entity recognition: “$1.2B” understood as monetary value
- Date and time parsing: “Q3 FY2024” resolved to specific periods
- Financial abbreviation handling: “YoY,” “EBITDA,” “P/E” processed correctly
The Competitive Advantage
📊 Performance Results:
- 15% improvement in stock movement prediction accuracy
- Real-time sentiment analysis across global markets
- Automated report generation saving analysts hours daily
Bloomberg’s domain-specific approach created a defensive moat—competitors can’t replicate without similar financial data access and domain expertise.
🛡️ Pattern 3: The Modular Enterprise Platform
“When Security and Scale Both Matter”
JPMorgan’s Fraud Detection Ecosystem
JPMorgan Chase protects transactions for nearly 50% of American households—a scale that demands both real-time processing and regulatory compliance. Their challenge: detect fraudulent patterns across millions of daily transactions while maintaining audit trails for regulators.
The solution combined GraphRAG (for relationship analysis), streaming architectures (for real-time detection), and compliance layers (for regulatory requirements) into a unified platform.
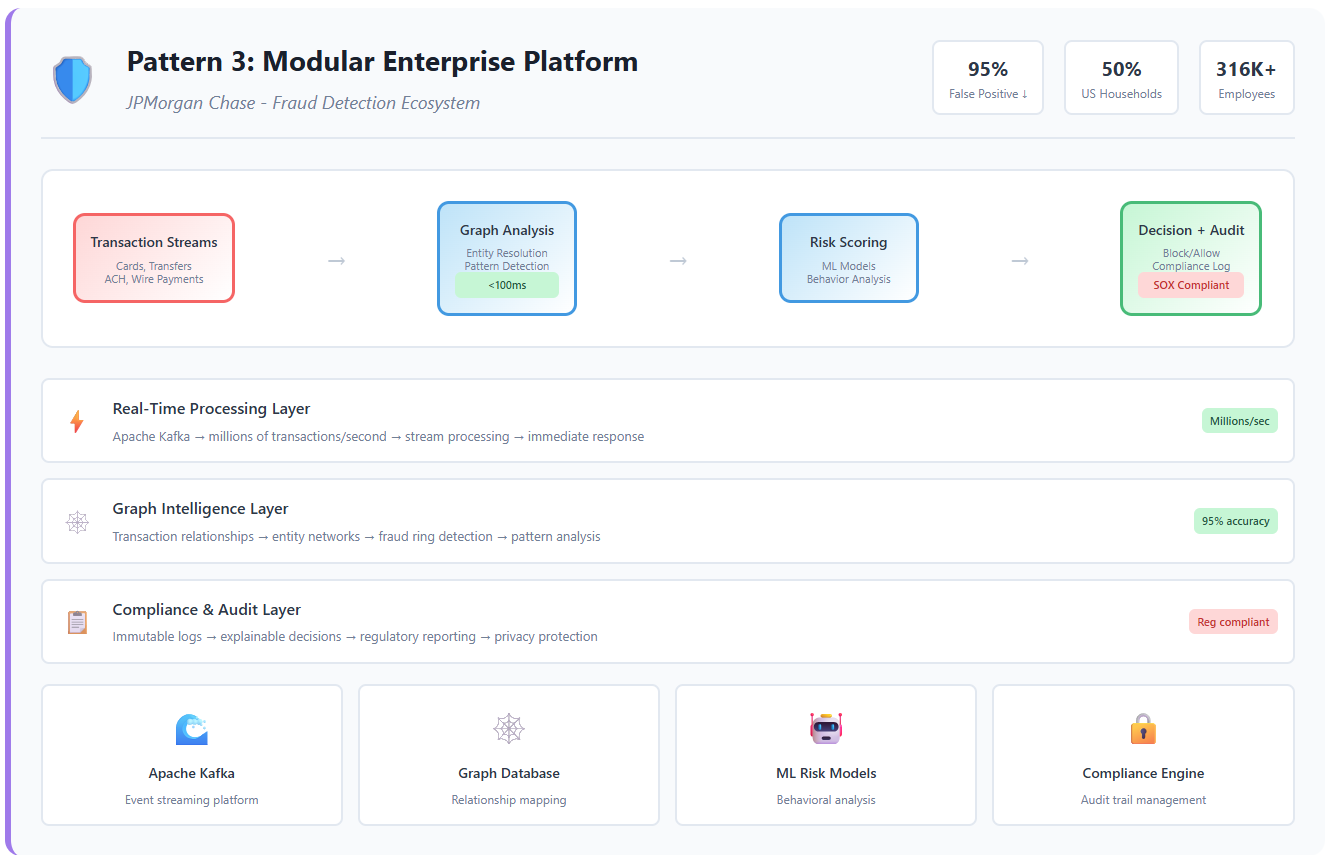
Architecture Innovation: Real-Time Graph Intelligence
🕸️ Graph Databases for transaction relationship mapping:
Account A → transfers to → Account B
→ similar patterns → Known fraud ring
→ geographic proximity → High-risk location
→ time correlation → Suspicious timing
⚡ Real-Time Processing for immediate detection:
- Event streaming via Apache Kafka processing millions of transactions/second
- In-memory graph updates for instant relationship analysis
- ML model inference with <100ms latency requirements
📋 Compliance Layers for regulatory requirements:
- Immutable audit trails for every decision
- Explainable AI outputs for regulatory review
- Privacy-preserving analytics for cross-bank fraud detection
The Security + Scale Achievement
🎯 Risk Reduction Results:
- 95% reduction in false positives for AML detection
- 15-20% reduction in account validation rejection rates
- Real-time protection for 316,000+ employees across business units
JPMorgan’s modular approach enables component-wise scaling—they can upgrade fraud detection algorithms without touching compliance systems.
🎯 Key Pattern Recognition
The Meta-Pattern Behind Success
Analyzing these three leaders reveals the architectural DNA of successful RAG:
🧩 Domain Expertise + Custom Data + Right Architecture
- Tempus: Medical expertise + clinical data + hybrid ML-RAG
- Bloomberg: Financial expertise + market data + domain-specific models
- JPMorgan: Banking expertise + transaction data + modular compliance
🚫 Generic Solutions Rarely Scale to Enterprise Needs
The companies spending $15K/month on Pinecone for 100 documents are missing the point. Enterprise RAG isn’t about better search—it’s about business-specific intelligence that understands domain context, relationships, and real-time requirements.
💎 Business Value Comes from the Combination, Not Individual Components
- Tempus’s value isn’t from GraphRAG alone—it’s GraphRAG + time-series analysis + medical literature
- Bloomberg’s advantage isn’t just custom embeddings—it’s embeddings + real-time data + financial reasoning
- JPMorgan’s protection isn’t just fraud detection—it’s detection + compliance + real-time response
The Implementation Reality
⚠️ Warning: These architectures require substantial investment:
- Tempus: $255M funding, years of data collection
- Bloomberg: Decades of financial data, custom model training
- JPMorgan: Enterprise-scale infrastructure, regulatory expertise
But the defensive moats they create justify the investment. Competitors can’t simply copy the architecture—they need the domain expertise, data relationships, and operational scale.
📊 Pattern Comparison Matrix
| Pattern | Investment Level | Time to Value | Defensive Moat | Best For |
|---|---|---|---|---|
| Hybrid Intelligence | $10M+ | 12-18 months | Very High | Multi-modal domains |
| Domain Specialist | $5M+ | 6-12 months | High | Industry-specific expertise |
| Modular Enterprise | $20M+ | 18-24 months | Extremely High | Regulated industries |
Success Indicators
- Clear domain expertise within the organization
- Proprietary data sources that competitors can’t access
- Specific business metrics that RAG directly improves
- Executive support for multi-year architectural investments
🔨 THE COMPONENT MASTERY – “Best Practices That Actually Work”
🧭 The Five Critical Decisions
The leap from proof-of-concept to production-grade RAG hinges on five architectural decisions. Get these wrong, and even the most sophisticated stack will flounder. Get them right—and you build defensible moats, measurable ROI, and scalable AI intelligence. Let’s walk through the five decisions that separate billion-dollar deployments from costly experiments.

🧩 Decision 1: Chunking Strategy – “The Foundation Everything Builds On”
❌ Naive Approach: Fixed 512-token chunks
- Failure rate: Up to 70% in enterprise-scale deployments
- Symptom: Context fragmentation, hallucinations, missed facts
✅ Best Practice: Semantic + Structure-Aware Chunking
- Mechanism: Split by headings, semantic units, and entity clusters
- Tools:
Unstructured.io,LangChain RecursiveSplitters,custom regex parsers
🏥 Real-World Example: Apollo 24|7
- Problem: Patient history scattered across arbitrary chunks
- Solution: Chunking based on patient ID, date, and medical entities (diagnoses, labs, medications)
- Result: ₹21:₹1 ROI, 44 hours/month saved per physician
🧱 Evolution
Basic LangChain splitter → Document-aware chunker (Unstructured.io) → Medical entity chunker (custom Python)
🔎 Decision 2: Retrieval Strategy – “Dense vs. Sparse vs. Hybrid”
⚖️ The Trade-off
- Dense: Captures semantics
- Sparse: Captures exact terms
- Hybrid: Captures both
🧪 Benchmark: Microsoft GraphRAG
- Hybrid retrieval outperforms naive dense or sparse by 70–80% in answer quality
🧠 When to Use What
| Use Case | Strategy |
|---|---|
| Semantic similarity | Dense only |
| Legal citations, audits | Sparse only |
| Enterprise Q&A | Hybrid |
⚖️ Real Example: LexisNexis AI Legal Assistant
- Dense: Interprets legal concepts
- Sparse: Matches citations and jurisdictions
- Outcome: Millions of documents retrieved with 80% user adoption
📚 Decision 3: Re-ranking – “The 20% Effort for 40% Improvement”
🎯 The ROI Case
- Tool: Cohere Rerank / Cross-encoders
- Precision Gain: +25–35%
- Cost: ~$100/month at moderate scale
🤖 When to Use It
- Corpus >10,000 docs
- Answer quality is critical
- Legal, healthcare, financial use cases
🔁 What It Looks Like
Top-20 retrieved → Reranked with cross-encoder → Top-5 fed to LLM
🏦 Worth It?
- For systems like Morgan Stanley’s assistant or Tempus AI’s medical engine—absolutely
🗃️Vector Database Selection – “Performance vs. Cost Reality”
📊 Scale Thresholds
| Scale | DB Recommendation | Notes |
|---|---|---|
| <1M vectors | ChromaDB | Free, in-memory or local |
| 1M–100M | Pinecone / Weaviate | Managed, scalable |
| 100M+ | Milvus | High-perf, enterprise |
💸 Hidden Costs
- Index rebuild time
- Metadata filtering limits
- Multi-tenant isolation complexity
🧮 Real Decision Matrix
Data size → Retrieval latency need → Security/privacy → Budget → DB choice
🧠 Decision 5: LLM Integration – “Quality vs. Cost Optimization”
🪜 The Model Ladder
| Task | LLM Choice | Notes |
|---|---|---|
| Complex reasoning | GPT-4/Gemini pro | Best in class, expensive |
| High volume Q&A | GPT-4.1 nano / Gemeni Flash | 10x cheaper, good baseline |
| Privacy-sensitive | LLaMA / Mistral / Qwen | Local deployment, cost-effective |
📉 Performance vs. Cost
| Component | Basic Setup Cost | Scaled Cost | Performance Gain |
|---|---|---|---|
| Chunking Upgrade | $0 → $2K | $5K | 20–40% |
| Re-ranking | $100/month | $1K/month | 30% |
| Vector DB | $0 (Chroma) | $10K–50K | 0–10% (if tuned) |
| LLM Optimization | $500–$50K | $100K+ | 10–90% |
RAG isn’t won at the top—it’s won in the components. The best systems don’t just choose good tools; they make the right combination decisions at every layer.
The 20% of technical decisions that drive 80% of business impact? They’re all here.
🚀THE SCALABILITY PATTERNS – “From Prototype to Production”
A weekend hack is enough to prove that RAG works. Scaling the same idea so thousands of people can rely on it every hour is a different game entirely. Teams that succeed learn to tame three dragons—data freshness, security, and quality—without slowing the system to a crawl or blowing the budget. What follows is not a checklist; it is the lived experience of companies that had to keep their models honest, their data safe, and their users happy at scale.
⚡ Challenge 1 — Data Freshness
“Yesterday’s knowledge is today’s liability.”
Most early-stage RAG systems treat the vector index like a static library: load everything once, then read forever. That illusion shatters the first time a customer asks about something that changed fifteen minutes ago. Staleness creeps in quietly—at first a wrong price, then a deprecated API, eventually a flood of outdated answers that erodes trust.
The industrial-strength response is a real-time streaming architecture. Incoming events—whether they are Git commits, product-catalog updates, or breaking news—flow through Kafka or Pulsar, pick up embeddings in-flight via Flink or Materialize, and land in a vector store that supports lock-free upserts. The index never “rebuilds”; it simply grows and retires fragments in near-real time. Amazon’s ad-sales intelligence team watched a two-hour ingestion lag shrink to seconds, which in turn collapsed campaign-launch cycles from a week to virtually instant.
Kafka stream → Flink job (generate embeddings) → upsert() into Pinecone
🔐 Challenge 2 — Security & Access Control
“Just because the model can retrieve it doesn’t mean the user should see it.”
In production, every query carries a security context: Who is asking? What are they allowed to read? A marketing intern and a CFO might type identical questions yet deserve different answers. Without enforcement the model becomes a leaky sieve—and your compliance officer’s worst nightmare.
Mature systems solve this with metadata-filtered retrieval backed by fine-grained RBAC. During ingestion, every chunk is stamped with attributes such as tenant_id, department, or privacy_level. At query time, the retrieval call is paired with a policy check—often via Open Policy Agent—that injects an inline filter (WHERE tenant_id = "acme"). The LLM never even sees documents outside the caller’s scope, so accidental leakage is impossible by construction. Multi-tenant SaaS vendors rely on this pattern to host thousands of customers in a single index while passing rigorous audits.
🧪 Challenge 3 — Quality Assurance
“A 1% hallucination rate at a million requests per day is ten thousand problems.”
Small pilots survive the occasional nonsense answer. Public-facing or mission-critical systems do not. As query volume climbs, even rare hallucinations turn into support tickets, regulatory incidents, or—worst of all—patient harm.
The fix is a layered validation pipeline. First, a cross-encoder or reranker re-scores the candidate passages so the LLM starts from stronger evidence. After generation, a second, cheaper model—often GPT-3.5 with a strict rubric—grades the draft for relevance, factual grounding, and policy compliance. Answers that fail the rubric are either regenerated with a different prompt or routed to a human reviewer. In healthcare deployments the review threshold is aggressive: any answer below, say, 0.85 confidence is withheld until a clinician approves it, and every interaction is written to an immutable audit log. This may add a few hundred milliseconds, but it prevents weeks of damage control later.
📈 The RAG Scaling Roadmap
Every production journey hits the same milestones, even if the signage looks different from one company to the next.
- MVP – “Prove it works.” A handful of documents, fixed-length chunks, dense retrieval only, GPT-3.5 or a local LLaMA. Everything fits in Chroma or FAISS on a single box. Ideal for hackathons, Slack bots, and stakeholder demos.
- Production – “Users rely on it.” Semantic or structure-aware chunking replaces naïve splits. Hybrid retrieval (BM25 + vectors) and reranking raise precision. Metadata filters enforce permissions. Monitoring dashboards appear because somebody has to show uptime at the all-hands.
- Enterprise Scale – “This is critical infrastructure.” Data arrives as streams, embeddings are minted in real time, and the index updates without downtime. Multi-modal retrieval joins text with images, tables, or logs. Validation steps grade every answer; suspicious ones escalate. Cost dashboards, usage quotas, and SLA alerts become as important as model accuracy.
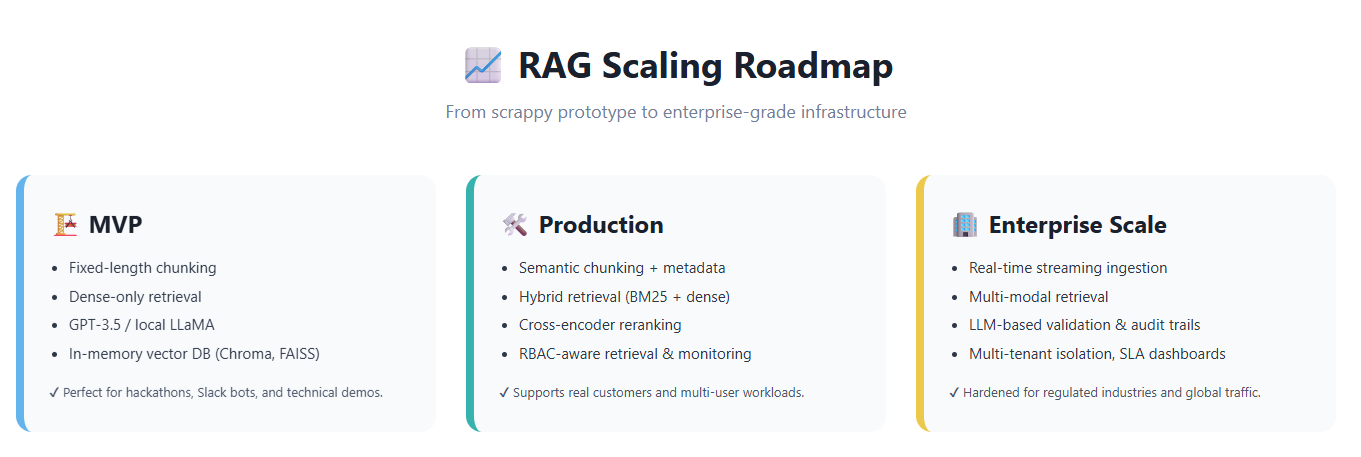
Scaling RAG is not an exercise in adding GPUs—it is an exercise in adding discipline. Fresh data, enforced permissions, continuous validation: miss any one and the whole tower lists.
If your system is drifting, it is rarely the fault of the LLM. Look first at the pipeline: are yesterday’s documents still in charge, are permissions porous, or are bad answers slipping through unchecked? Solve those, and the same model that struggled at one hundred users will thrive at one million.
🔮THE EMERGING FRONTIER – “What’s Coming Next”
🌌 The Next Horizon
The future isn’t waiting—it’s already here. Three emerging trends are reshaping the Retrieval-Augmented Generation landscape, and by 2026, the early adopters will have set the new benchmarks. Here’s what you need to watch.
🚀 Three Game-Changing Trends
🤖 Trend 1 — Agentic RAG: Smart Retrieval on Demand
- What: Intelligent agents autonomously determine what information to fetch and how best to retrieve it.
- Example: A strategic consulting assistant plans multi-step data retrieval —
“Fetch Piper’s ESG 2024 report, validate against CDP carbon figures, and highlight controversial media insights.” - Why it Matters: Dramatically reduces token usage, enhances accuracy, and significantly accelerates research workflows.
- Timeline: Pilot projects active → Early adoption expected 2025 → Mainstream by 2026
🖼️ Trend 2 — Multimodal Fusion: Breaking the Boundaries of Text
- What: Unified retrieval across text, images, audio, and structured data.
- Example: PathAI integrates medical imaging with clinical notes and genomic data into a single analytic pass.
- Why it Matters: Eliminates domain-specific silos, enabling models to concurrently “see,” “hear,” and “read.”
- Timeline: Specialized use cases live now → General-purpose SDKs by mid-2025
⚡ Trend 3 — Real-Time Everything: Instant Information Flow
- What: Streaming ingestion, real-time embeddings, and instant query responsiveness.
- Example: Financial copilots merge market tick data, Fed news, and social sentiment within milliseconds.
- Why it Matters: Turns RAG into a live decision support layer, not just a passive archive searcher.
- Timeline: Already deployed in finance and ad-tech → Expanding to consumer apps next
💡 Strategic Investment Guidance
| Horizon | Prioritize Adoption | Optimize Current Capabilities | Consider Delaying |
|---|---|---|---|
| 0–6 months | Real-time metadata streaming | Chunking refinements, hybrid retrieval | Early agentic workflows |
| 6–18 months | Pilot agentic use-cases | Multimodal POCs | Full-scale multimodal overhauls |
| 18–36 months | Agent frameworks at scale | — | Replace aging RAG 1.0 infrastructure |
🏁THE FINAL INSIGHT – “The Meta-Pattern Behind Success”
🧠 The Universal Architecture of Winning RAG Systems
Across industries and use cases—from finance to medicine, legal to logistics—the same pattern keeps emerging.
Success doesn’t come from having the flashiest model or the biggest vector database. It comes from the right combination of four ingredients:

You can’t outsource understanding. Every breakthrough case—Morgan Stanley’s advisor tool, Bloomberg’s financial brain, Tempus’s clinical intelligence—started with one hard-won insight: “Build RAG around the problem, not the other way around.”
“RAG success isn’t about technology—it’s about understanding your business problem deeply enough to choose the right solution.”
💼 The Strategic Play
Want to build a billion-dollar RAG system? Don’t start by picking tools. Start by asking questions:
- What type of knowledge do users need?
- What is the cost of a wrong answer?
- Where does context come from—history, hierarchy, real-time data?
- What decision is this system actually supporting?
From there, design your stack backward—from outcome → to architecture → to components.
“The companies generating billions from AI didn’t start with perfect RAG. They started with clear problems and built solutions that fit.”
🔑 The One Thing to Remember
If you take away just one insight from this exploration of RAG architectures, let it be this:
RAG isn’t magic. It’s engineering.
And like all engineering, success comes from matching the solution to the problem—not forcing problems to fit your favorite solution. The $50 million question isn’t “How do we implement RAG?” It’s “What problem are we actually trying to solve?”
Answer that honestly, and you’re already ahead of 60% of AI initiatives.
The revolution continues—but now you know which battles are worth fighting.
